Wholesale Virtualisation and Selective QinQ
Recently I have been working on a solution to provide Wholesale Access to hosted VMs. Several of my customers have “Cloud Environments” - call it IaaS, virtualisation, a fad or whatever, this is something that I have been asked to come up with a solution for more than once.
To explain the requirements outlined in this article, I should give a little background on the design requirements and constraints. For some of my customers the standard build is to include 2x VLANs for each Customer - a Live VLAN, and an Internal/Backend network. If the customer has more than one VM in a cluster then all servers will share these VLANs. Unfortunately this quickly runs through the available VLANs (And we love that the Nexus 5k only supports 512 vlans). This limited the number of customers in a single VM cluster, due to VLAN limitations inherent in Data Centre switches.
To scale out from these limits, and dealing with network growth and evolution additional clusters have been built and added. Each VM Cluster is self contained, including its own Compute, Network and Storage infrastructure. Within a single cluster we have allowed the use of the full range of VLANs from 1 through to 4094.
As happens with many successful ventures, customer numbers have grown considerably and with it came the requirement for third parties to be able to host their own customers within these VM clusters. I call these third parties “Wholesale Customers”, because they are buying services in bulk from the Service Provider and then splitting them up between their own distinct customers.
As a “value add” we have allowed these wholesale customers to interconnect directly with the switching fabric to we trunk the VLANs across to them as needed. This allows the Wholesale Customer to add their own services to the VLANs, or to integrate these VMs inside customer WAN VRFs etc.
The problem comes when the Wholesale Customer has VMs in more than one cluster. Do they need to order a cross-connect to each cluster or can we aggregate VMs from all clusters across a single link? Due to the VLAN reuse policy in action within the clusters, traditional switching and trunking would cause an issue as it is possible for a wholesale customers separate VMs to exist in the same vlan-id in different clusters.
**Config Snippet**interface GigabitEthernet0/1 description Trunk to Cluster 1 port-type nni switchport trunk allowed vlan none switchport mode trunk service instance 1 ethernet encapsulation dot1q 200 bridge-domain 3600 ! service instance 2 ethernet encapsulation dot1q 201 bridge-domain 3601 ! interface GigabitEthernet0/2 description Trunk to Cluster 2 port-type nni switchport trunk allowed vlan none switchport mode trunk service instance 1 ethernet encapsulation dot1q 200 bridge-domain 3700 ! service instance 2 ethernet encapsulation dot1q 301 bridge-domain 3701 ! interface GigabitEthernet0/3 description Trunk to Customer A port-type nni switchport trunk allowed vlan none switchport mode trunk service instance 2 ethernet encapsulation dot1q 300 second-dot1q 1-4094 rewrite ingress tag pop 1 symmetric bridge-domain 3600 ! service instance 3 ethernet encapsulation dot1q 400 second-dot1q 1-4094 rewrite ingress tag pop 1 symmetric bridge-domain 3700 ! interface GigabitEthernet0/4 description Trunk to Customer B port-type nni switchport trunk allowed vlan 3601,3701 switchport mode trunk
A Solution is needed
As Im sure many of my readers know, we could easily use dot1q-tunelling (otherwise called QinQ) to encapsulate traffic from each cluster inside an outer vlan (Referred to as a Service VLAN or S-VLAN). The downside to this solution is that each wholesale customer would need a separate QinQ port per cluster, and this could get very unwieldy very quickly. I needed to come up with a solution that would scale better than this, without requiring needless wasted ports within the switching infrastructure.
We outlined the following requirements:
Allow full VLAN range use within a cluster
Allow each the same vlan-id used in different clusters be sent to the same wholesale customer
Allow for future integration with the proposed MPLS routing between clusters and DCs
Be economic on scale and reduce wastage
Allow the same wholesale handoff infrastructure to be used by multiple customers
I knew that I could accomplish these requirements using a Service Provider technology called “Selective QinQ”. Essentially this allows a single incoming port to determine the S-VLAN to according to certain attributes of the incoming packet. With this in mind I went through the various vendor offerings on this front, and in the end we settled on using the new Cisco ME3600-X Metro Switching platform.
Enter the Cisco ME3600
The Cisco ME3600 is a new offering in Cisco Metro Ethernet series of switches. The Metro switches, as their name implies, are aimed at Service providers building large cross-city ethernet networks. These type of networks have very similar requirements to those I listed above - in particular facilitating the carriage of distinct customer traffic across a common backbone while maintaining scalability and economic hardware investment.
The ME3400 has long been the bastion of this family of switches, being used all around the world in the basement of many buildings providing access into Service Provider networks, so naturally this was the first place I looked for a solution. We quickly determined that the new switch on the block, the ME3600, could meet both our current and future requirements so we ordered a pair of these for our tests.
This new switch introduces some new features over and above the ME3400, in keeping with the definitions of the Metro Ethernet Forum (MEF). In particular it utilizes three particular features that might be new to engineers used to working with traditional Cisco Catalyst switches.
** Ethernet Virtual Connection (EVC):** An EVC is a logical collection of interfaces within a service provider network that is linked to a particular end customers network. These can be either point-to-point or multipoint-to-multipoint.
Bridge Domain: A Bridge Domain is broadcast domain that is local to the switch, but is not limited to a certain VLAN. This allows a set of Service Instances on ports to be treated the according to a defined pattern.
Ethernet Flow Point: An Ethernet flow point is a logical flow or set of traffic within an EVC and Bridge Domain. On the ME3600 an EFP is represented as a Service Instance on an individual interface. Service Instance numbers are unique to the interface and do not relate to the same instance number on another interface.
The Design
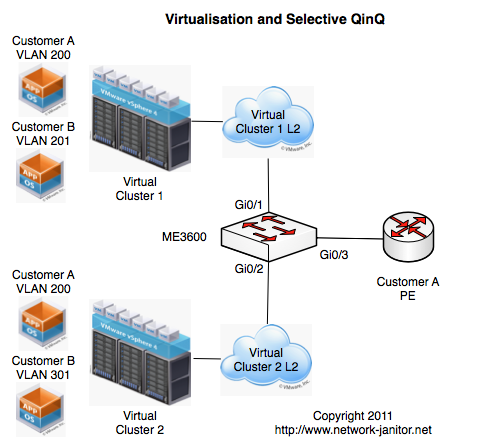
Now essentially my design was to take the ME3600 switch and turn it on it head. In my design WE were going to be the end customer, and the wholesale customer was going to be the “Service Provider” or upstream side. As is shown in the diagrams above the Layer 2 network from each cluster is configured with a trunk link into the ME3600. On ingress the switch would match based on incoming VLAN and assign traffic to a bridge domain associated with the wholesale customer. One bridge domain, per Wholesale Customer, per Cluster. On egress the switch will assign a set S-VLAN as determined by the bridge domain of the traffic.
If you refer to the Config Snippet above, and look specifically at the config for Interface GigabitEthernet0/1 (The link to Cluster 1) you will see two seperate Service Instances defined:
Instance 1 is configured to match incoming traffic with the 802.1Q vlan-id of 200, and assign it to bridge domain 3600.
Instance 2 is configured to match incoming traffic with the 802.1Q vlan-id of 201, and assign it to bridge domain 3601
Most of this is straight forward and as you can see, Interface GigabitEthernet0/2 is configured in a similar fashion. You should note from the diagram that Customer A has two VMs each of which is located in “VLAN 200”.
The interesting work happens on the ports heading to the Wholesale Customers. There are two possible options, and I have shown both of them in the Config Snippet above.
As is shown on Interface GigabitEthernet0/4, you can simply configure the outbound port as a trunk. In this case all traffic in the bridge domain will be encapsulated with the S-VLAN tag matching the Bridge Domain id. In the case of Customer B this would be vlans 3601 and 3701.
The other more flexible option (and the one I have chosen to go into production with), requires a little extra configuration but is a lot more flexible. As shown on Interface GigabitEthernet0/3, I have configured two Service Instances - one for each Bridge Domain. Service Instance 2 is linked to Bridge Domain 3600 and is configured to take an packets inbound on the port with an S-VLAN of 300 and dump it into the Bridge Domain. The rewrite rule essentially says to reverse the procedure for any packets egressing GigabitEthernet0/3. Service Instance 3 takes traffic in Bridge Domain 3700 and associates it with S-VLAN 400.
In the example included here, The Customer A VM in Cluster 1 would have an S-VLAN of 300 and a C-VLAN of 200. The VM in Cluster 2 would have an S-VLAN of 400 and a C-VLAN of 200. When they traverse through the Wholesale Customer network they will remain distinct and separated. The biggest advantage to using the second method is that you are able to set an S-VLAN that is suitable for the Wholesale Customer without worrying about having that VLAN clash with those inside your own network.
There are many other features possible on the ME3600 utilising Service Instances and Bridge Domains that I have not covered here. These include Layer2 Protocol tunneling, Split Horizon groups to ensure certain ports in a Bridge Domain do not share traffic which can be utilised in to control loops in the network.
I hope this has been a useful introduction to the ME3600 and Selecting QinQ, and in particular using it in a location that it was not originally intended.
Feel free to add your own comments and view points, as this is still a developing design so I am happy for all your input.
NOTE: It should be noted that this switch is essentially transparent to your network, and that you are also bridging the Layer2 in your network with that of a third party, and all measures should be taken to reduce the impact of third party network problems taking out your own network.